How I used AI in Hunchle
Subscribe to my newsletter (it's free!)
I used AI in a big way to build Hunchle. I figured it would be useful to write this post to share my experience and to document what coding with AI looks like today.
There were two major ways I used LLMs in Hunchle, a trivia app:
1. Generating questions
In an ideal world, I’d generate 30,000 questions by myself, custom-crafted the way I like quiz questions. However, that was more of a time investment than I’d have liked. So, I decided to use AI (ChatGPT, Gemini, and Grok mostly) to generate some questions for me.
“General” knowledge
Most of these were run-of-the-mill questions that wouldn’t really tickle trivia enthusiasts the right way. Questions that were straightforward without multiple hints - like, “What’s the capital of Canada?” or “Who wrote Romeo & Juliet?”. You either knew it or you didn’t. I decided those would have to do for now.
An aside: I think this is going to be a common thing with AI, where you trade off getting more optimal results to gain time. TBH, as an industry, software engineers have been creating sub-optimal software (under the direction of “get the next feature out ASAP” & “bug fixing doesn’t get you promotions”), so how much worse can things get with AI? I think it’s possible it could get MUCH worse. AI can generate code, and therefore bugs, at breakneck speed. With human-written code, the slowness in getting new code out acts (unintentionally) as brakes against new bugs being added. With AI, you frequently have 1000 lines of new code, with entire working sections being completely rewritten. This means you are left overwhelmed, and in a worse state than when everyone was manually coding. Interesting times lie ahead.
Unusable questions
Some other questions were plain useless. Here’s an actual example:
Q: This Olympic sport, whose name comes from the French word for 'fencing',
involves a foil, épée, or sabre. What is it?
A: Fencing
I hope I don’t have to explain that one. Here’s another one, which I will likely need to explain:
Q: This HBO series, set in a medieval fantasy world, became famous for its
shocking deaths and dragons. What is it?
A: Thrones
What’s up with that? The right answer is “Game of Thrones”, but here the AI simply prints “Thrones”. Here’s what happened. The instructions I’d given were to prefer 1-word answers if possible (for example, using only the last name if the answer was the name of a person). I’d also instructed that if that wasn’t possible, the AI should specify the number of words in the answer. Here, instead of stating “3 words” and leaving the answer as “Game of Thrones”, it decided to go for the former - clearly incorrect to a human - approach and simply entered “Thrones”.
Getting it to generate a good mix of difficulty for the questions was another entirely complicated ritual. I have nothing successful to share here yet, so I’ll simply leave this as a hopeful note for the future.
2. Generating hints
One of the earliest pieces of feedback I got was that the questions were too hard. As people in any field are likely to do, I’d severely overestimated the familiarity anyone outside the field of trivia had with any of these things. One suggestion to fix this was to use multiple choice questions, but I didn’t like that route where you’d get a dopamine hit simply out of luck. I chose to go with providing hints, and leveraging AI to “personalize” them based on a user’s guess. I used the Gemini API for this, and this led to a BUNCH of problems.
Often, the LLM would provide the answer as a hint!
This was a nightmare failure scenario, where the LLM is violating your #1 constraint: don’t simply give away the answer! The impact of the error here is not extremely serious, since this is a fun game after all, but imagine if a company used this for something like prompting a user with a hint for their “Security Question”. The fallout could bankrupt a company. I tried a few things to get around this. First, I explicitly instructed it multiple times, not to provide the answer. I realized it was still doing so, for example, in a question about Peter Pan’s nemesis (Captain Hook). The AI hint suggested the user think about a “hook-handed character”. I realized it may have not realized that a “hook” (object) is effectively the same thing as “Captain Hook” (the character) in this case. So, I added a further instruction not to use the word at all. It would still sometimes slip in the answer, so I added code to search the “hint string” for the occurrence of the answer, and then redact it. This led to a couple of other fails where it would present hints that were now leaked because of redaction, as seen here:
Question: What is the chemical symbol for silver?
Correct Answer: Ag
User Answer: Au
Hint: You're right that "Au" is a chemical symbol! However, it represents a different
precious metal. Think about the origin of the symbol and which langu<REDACTED>e
it comes from.
Useless hints
Sometimes, the LLM would simply restate the question as a hint, leading to a frustrating user experience. Here’s an example of that:
Q: What is the name of the main protagonist of Star Wars: The Return of the Jedi?
(2 words)
Correct Answer: Luke Skywalker
User Answer: <blank>
Hint generated:
"Okay, here's a hint:
Think about the young farm boy who becomes a Jedi. His last name is a common one!"
Useless and even misleading in some sense. Here’s another one:
A: Jennifer Lawrence
Hint generated:
"Okay, no problem! Here's a hint to help you:
This actress's first name is the same as a common type of tree."
What? Did it confuse “Jennifer” with the “Juniper” tree?
Here’s another bad hint (the first word in the answer is “The” and not “Ariel”):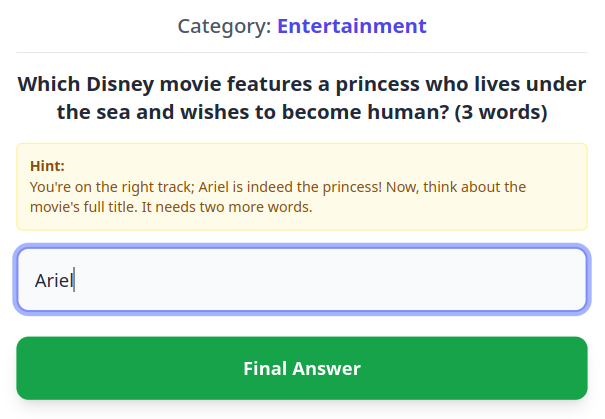
Room for improvement outside LLMs
Not every problem is related to LLMs. Designing a system to provide hints is quite challenging, as I’m learning! Unfortunately, each user is unique, and each user knows about a unique set of facts stemming from what they have learned or experienced in their life (just like me). This makes it really difficult to craft good hints that work across users without data on what users already know. If you have any ideas, hit me up! Here are a couple of examples of this in action:
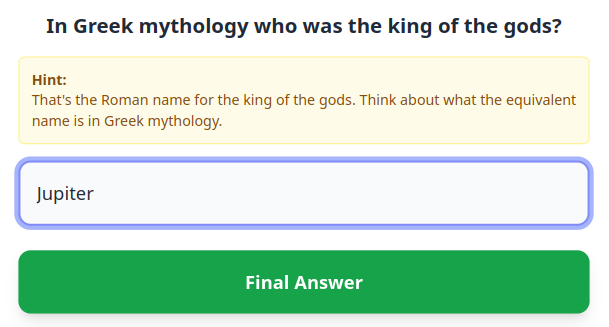
If the user doesn’t know the Greek name for Jupiter, they are out of luck. The hint only helps those who know that Jupiter-Zeus are simply Roman-Greek versions of the same god.
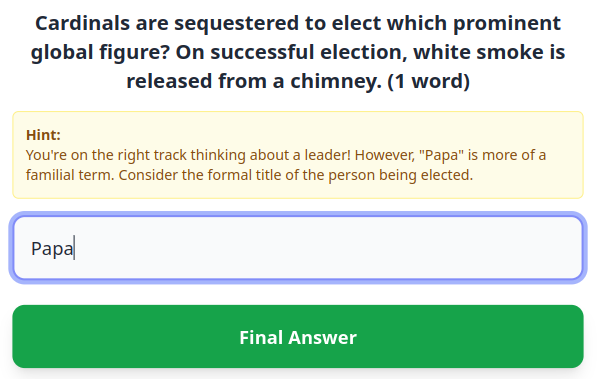
Here, the LLM treats “Papa” as the word “Dad” and not as the Spanish word for “Pope”. If the user meant the latter, this could be a confusing experience.
What I tried to fix this
I tried rewriting the prompt, and then decided I better A/B test it with my existing prompt. So, I got the LLM to write me another script that could read the questions and incorrect responses I’d gotten so far and feed them into the Gemini API calling one of two models with one of two prompts. I’d choose which one I’d prefer and it would give me a ranking.
I had to fine-tune what it generated - it generated a poor ranking algorithm, and I asked it to use an Elo-based system instead - but, the results surprised me. The verbose prompt seemed to give better “hints”, as did the older “stable” model. The newer “experimental” model led to worse results, which gave me some pause.
Here you can see some results.
Initial run, which simply showed how much I preferred a particular LLM+prompt (but not the level of the LLM+prompt it was up against). FWIW, both hints seem to not be very useful: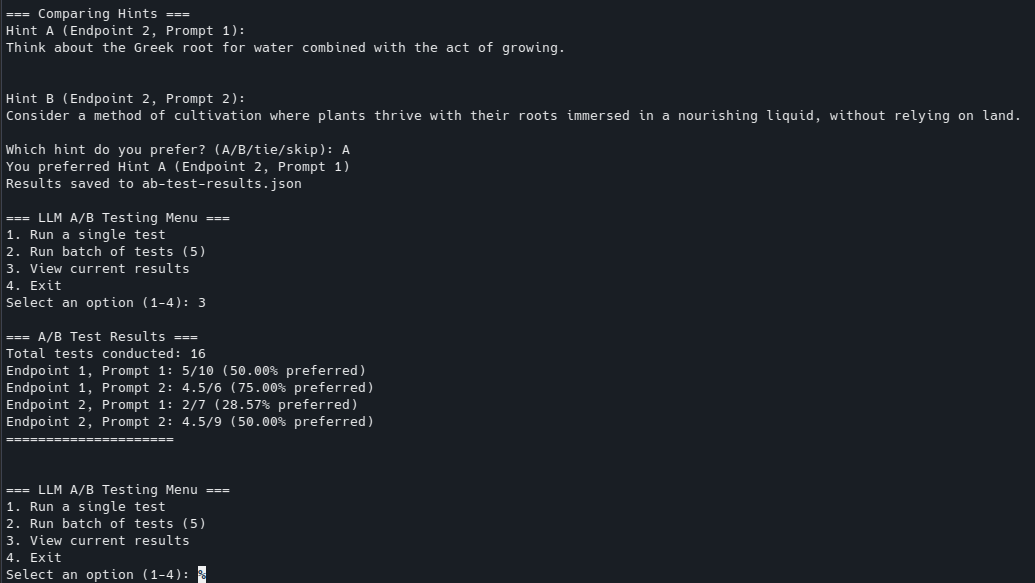
Run that used my Elo suggestion. This screenshot has some better hints: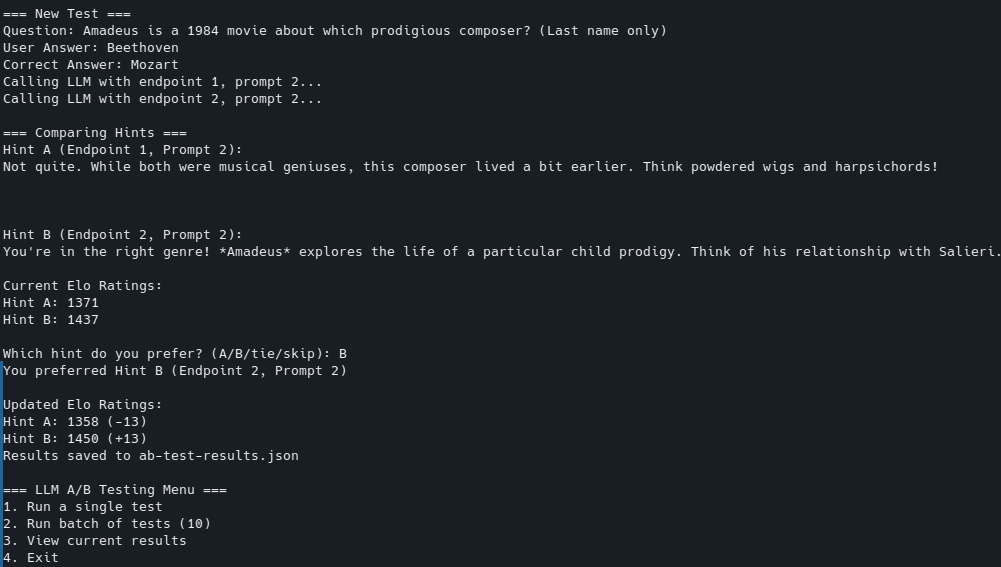
I likely need to fine-tune or train the LLM to give good hints, and as of now I’m not 100% sure how to do that. Watch this space!