Open AI Codex - coding with AI
Subscribe to my newsletter (it's free!)
I got to use the Open AI Codex API today, as part of the Open AI codex challenge. The challenge consisted of 5 problems, meant to be solved as quickly as possible, with the Codex available for help.
Clicking the “Codex it” button would get Codex to “parse” the problem statement, the comments in code and the method signature. Following that, it would write code that solved the problem. For the problems in the contest, the generated code either solved the problem completely or required only minor changes (<= 3 lines).
“Results”
I finished in 120th place, though this is one of those cases where you should definitely not trust the metrics. The website faced enough issues (see section below) that finishing the problems and getting a rank was more a measure of luck and persistence, and less of skill.
The time taken (by me and “average player”(s)) in the graph below is greatly exaggerated, thanks to the website issues documented in later sections.
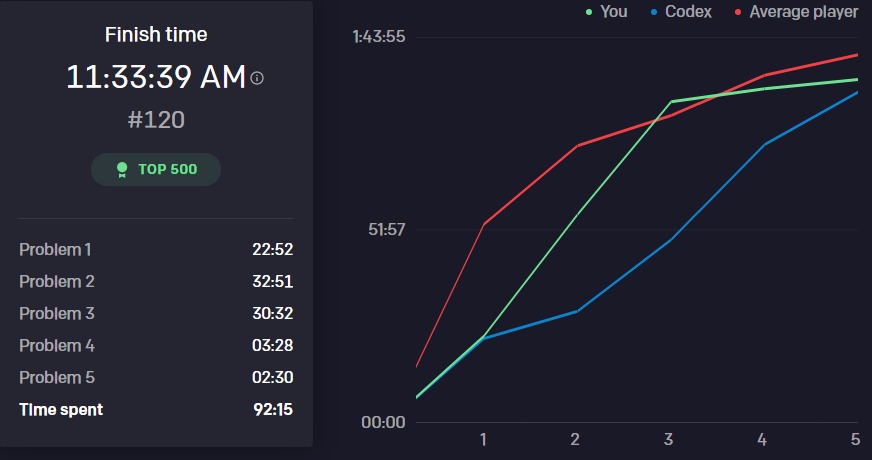
Thoughts
Overall, the Codex did a decent job in some areas (including code from modules; parsing; rough logic), and a not-so-decent job in others (getting logic 100% right; tests).
My process for solving the problems
Since I was interested in how the Codex would do, I would hit “Codex it” even if I knew how to solve the problem. From this point, I usually tried “debugging” the Codex code. This new programming vision that Open AI paints, points to a need for stronger code-reading and debugging skills, with code-writing skills shrinking in importance. However, this will depend a lot on how Codex performs - if Codex feels unreliable, developers may prefer writing code by themselves, as even with the googling & copy-pasting from Stack Overflow, the total time spent would be lower.
Codex is clearly great at parsing problem statements and coming up with code that aims to address the problem. I was caught a little off-guard with how Codex picked methods. Many methods were quite different from those I’d have chosen, and this made it a little harder for me to read and debug the code (more in problem details).
For problems that I could see the solution quickly to, the code-writing exercise was now effectively a code-review exercise! I would expect the same pitfalls exist as with normal code-reviews (bugs may not be caught; tests must be written).
Where Codex “shines”1 is in its ability to quickly digest a large number of modules and libraries and write code using those. I’d be interested in learning how much manual effort is involved in getting a new library “digested” by Codex. For example, in problem 2, “difflib” was recommended in the problem statement - did difflib have to be explicitly “ingested” by Codex at some point prior? Lastly, in some cases, Codex doesn’t save much time - if you are unfamiliar with the library, you have to read up on it to debug effectively, and this forms the bottleneck, not the code-writing process.
Regrets
Unfortunately, I didn’t really use Codex to “help” me code (Open AI has recommended using Codex as a “helper”, for example, by defining helper function signatures and having Codex implement it). This is partly because I wasn’t sure how long I had to work on the problems and, with the website constantly crashing, I wasn’t sure how long I would have access to Codex. In addition, once a problem was “solved”, I was not allowed to edit the code (or access Codex) any longer.
The future
I’d love to see what can be done with some curation/manual involvement to “direct” Codex. For example, Wikipedia “digests” a large amount of information with manual effort distributed across many humans. Can a similar model help Codex?
Can Codex “learn” from reviews? How portable is it (can it be used on a laptop? on a mobile?)? Codex could really change the world if it allowed users to code from mobile (as the typing experience is horrid) - even if the code is rough.
Codex’s true value probably lies in its ability to inspire and stretch the limits programmers set on their vision.
Challenge website problems
Almost as soon as the challenge started (at 10 AM PST), the website was failing to serve requests. Users got a lot of 503 (internal server error) and 504 (gateway timeout) errors, indicating that the Open AI servers were likely experiencing far more load than they were prepared for. As users likely quit trying to grapple with the system, the website slowly recovered.
Initially, nothing was displayed.
Then, the editor was displayed, but without the problem statement.
Then, the problem statement was discovered, but hitting “Codex it” would cause the website to hang (or respond very slowly).
Finally, with some luck, hitting submit may get you a response (or you might have to hit refresh and hope your code wasn’t lost). Needless to say, this led to a very frustrating experience for many (including myself) and allowed some to post some snarky tweets announcing that those “the death of programming” declarations were a bit premature.
These issues lasted throughout (at least until I finished all problems).
Problem details
Time to solve is given in minutes (approximated)
Problem 1
Statement
Given a(sic) the contents of a CSV file as csv_contents, return the difference in days between the date of the earliest and the oldest entry.
Code
from datetime import date
import pandas
def diff_days(csv_contents: str) -> int:
# TODO: your implementation here
lines = csv_contents.split("\n")
header = lines[0]
data = pandas.read_csv(io.StringIO(csv_contents))
oldest = data["Date"].min()
newest = data["Date"].max()
return (
date.fromisoformat(newest) - date.fromisoformat(oldest)
).days
# Examples
print(diff_days("Date,Price,Volume\n2014-01-27,550.50,1387\n2014-06-23,910.83,4361\n2014-05-20,604.51,5870"))
print(diff_days('Date\n2000-01-01\n2000-01-01\n'))
# The last expression evaluated is always shown when
# you run your code, just like a Jupyter notebook cell.
"Good luck!"
Modifications needed
None!
Comments
I was caught off-guard by the use of the “fromisoformat” and “io.StringIO” methods. I’d almost certainly have had to look up a way to do it, but this seems to work, so I didn’t look further. Also, the “header” variable isn’t used. I like that the read_csv method was used (rather than splitting by “,” - which could fail in some cases), which Open AI’s problem statement suggesting pandas usage might have helped with.
Time to solve
1 < x < 5
Problem 2
Statement
source and target are two strings each containing file contents. Return the number of lines you would need to insert and the number of lines you would need to delete to get to target from source.
Code
import difflib
from typing import Tuple
def diff_files(source: str, target: str) -> Tuple[int, int]:
"""
Returns the number of lines to add and delete to turn source into target.
"""
lines_to_insert = list()
lines_to_delete = list()
for group in difflib.SequenceMatcher(None, source.splitlines(), target.splitlines()).get_grouped_opcodes():
for tag, i1, i2, j1, j2 in group:
if tag == 'insert':
lines_to_insert += target.splitlines()[j1:j2]
elif tag == 'delete':
lines_to_delete += source.splitlines()[i1:i2]
elif tag == 'replace':
lines_to_delete += source.splitlines()[i1:i2]
lines_to_insert += target.splitlines()[j1:j2]
#print(tag)
#print(lines_to_insert)
#print(lines_to_delete)
return len(lines_to_insert), len(lines_to_delete)
# Examples
print(diff_files('Apple\nOrange\nPear', 'Apple\nPear\nBanana\nMango'))
print(diff_files('Apple\nOrange\nPear', 'Apple\nPear\nBanana'))
print(diff_files('\nz\ncW\nFe1by\n6X5\n\nsqFzv\nb', 'S\nxb3\n1\nlfJ1\nt9sqW\nUUUZE\n\n\n\nw\nqjT\ngGVBL\n\n'))
Modifications needed
Needed to add the “replace” branch.
Comments
This took a significant amount of time, as I initially assumed Open AI would have included the necessary code, with only logic bugs (this assumption held for other questions coincidentally). This meant I didn’t look up how the method was meant to be used immediately, rather trying to interpret it from code. As a result, my initial attempts involved trying to use a list instead of a set, etc. Interestingly the code that “OpenAI Codex” used (not sure why this is different than simply hitting the “Codex it” button) was much simpler.
Time to solve
15 < x < 60
Problem 3
Statement
Given a compressed message compressed (sic) and the prefix code tree used to encode it, decode and return the original message.
Code
from typing import Dict, Union
Tree = Dict[str, Union[str, "Tree"]]
def decompress(compressed: str, origTree: Tree) -> str:
# create a stack that will hold characters for the decoded message
result = []
tree = origTree
# iterate through the compressed message
for bit in compressed:
# move down the tree based on the bit
tree = tree[bit]
# if we've reached a leaf, add the character to the message
if isinstance(tree, str):
result.append(tree)
# start over at the root of the tree
tree = origTree
# return the final decoded message
return "".join(result)
# Examples
print(decompress('110100100', {'0': 'a', '1': {'0': 'n', '1': 'b'}}))
print(decompress('0111010100', {'0': {'0': 'x', '1': 'z'}, '1': 'y'}))
Modifications needed
Needed to replace some of the references to the “tree” variable with “origTree” (origTree was introduced by me; did not exist with the Codex code).
Comments
This surprisingly (to me) resulted in a compile error on the first run after “Codex it”. The fix was fairly simple once I had figured out how to parse the problem (thanks to having done similar problems earlier).
Time to solve
1 < x < 5
Problem 4
Statement
Parse the given Python source code and return the list of full-qualified paths for all imported symbols, sorted in ascending lexicographic order.
Code
import ast
from typing import List
def parse_imports(code: str) -> List[str]:
"""Parse the given Python source code and return the list of full-qualified paths for all imported symbols, sorted in ascending lexicographic order."""
tree = ast.parse(code)
imports = []
for statement in tree.body:
if isinstance(statement, ast.Import):
for name in statement.names:
imports.append(name.name)
elif isinstance(statement, ast.ImportFrom):
for name in statement.names:
imports.append(statement.module + "." + name.name)
return sorted(imports)
# Examples
print(parse_imports('import os'))
print(parse_imports('import os\nfrom typing import List'))
print(parse_imports('import os\nimport concurrent.futures\nfrom os import path as renamed_path\nfrom typing import (\n List, Tuple\n)'))
Modifications needed
Needed to delete an if branch (or some code under the “ImportFrom” branch).
Comments
I felt grateful that I had Codex to handle this problem. I would have likely approached it by parsing text, as I was not familiar with Python’s ast library. Having Codex write code that traversed the abstract syntax tree (AST) to solve the issue meant that the final product was more bug-proof than the text-parsing version I would have written.
I was pretty impressed by how the code solved the problem so well, and although a developer with more experience with the library may have written it differently, I was happy with the result.
Time to solve
1 < x < 5
Problem 5
Statement
You have several buckets whose sizes are represented by the list sizes. Find the number of different ways to arrange the buckets such that the first bucket’s size is greater than the second bucket’s size.
Code
import itertools
from typing import List
def count_arrangements(sizes: List[int]) -> int:
if len(sizes) < 2: return 0
arrangements = list(itertools.permutations(sizes))
return len([x for x in arrangements if x[0] > x[1]])
# Examples
print(count_arrangements([1, 3, 1]))
print(count_arrangements([1, 2]))
Modifications needed
Added the if condition (base case).
Comments
I was surprised at how well Codex handled this. Only the base-case needed to be handled, and again, the code is near perfect - the only change I might make is to use a generator instead of a list in the return.
Time to solve
1 < x < 2
Footnotes
“shines” — depending on how much manual effort is involved, I’m not convinced I can say it shines. ↩︎